SpeedMaximize LLM Speed
Get LLM Responses
25x Faster
Our intelligent model router automatically selects the fastest LLM, optimizing latency across OpenAI, Anthropic, DeepSeek and more, while maintaining quality.
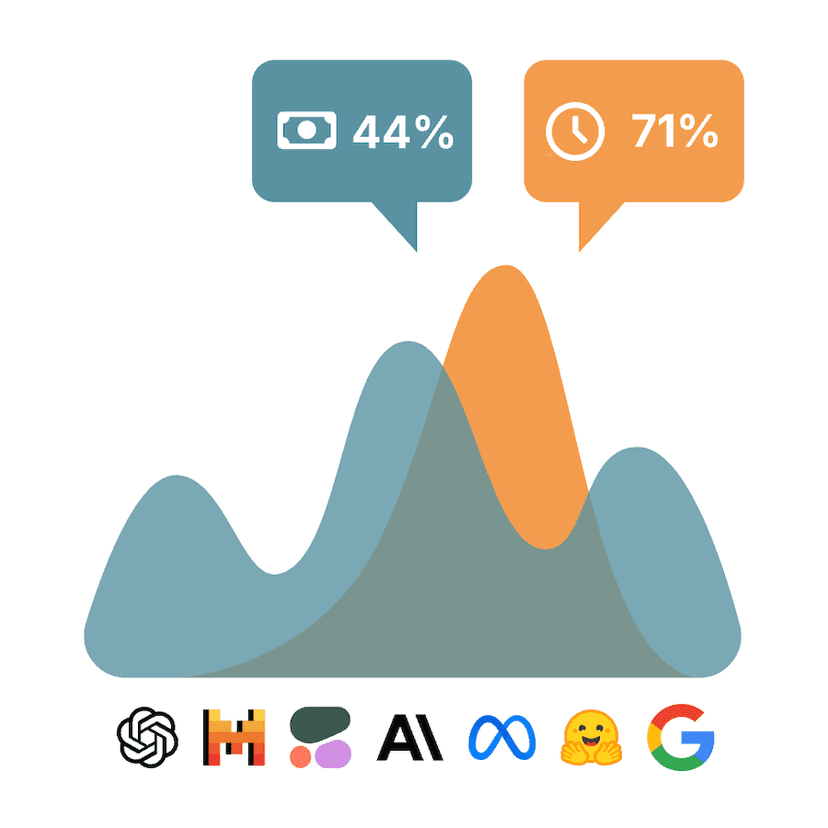
Average Routing Timeof our production clients
Models in Routing Mixfrom OpenAI, Anthropic, Google, Meta, DeepSeek, Mistral, Cohere
Maximize Speed, Minimize Latency. Automatically route to fastest-responding models while maintaining your quality standards. Stop waiting for LLM responses.
Smart Latency Optimization
Latency-Weighted Routing
Automatic Performance Updates
Optimize Across All Leading LLM Providers
Unlock Maximum Performance
Model comparisons reveal significant latency differences between similar-quality models like GPT-4o, Claude 3.5 Sonnet, and Gemini 1.5 Pro. Our router automatically routes to the fastest option.
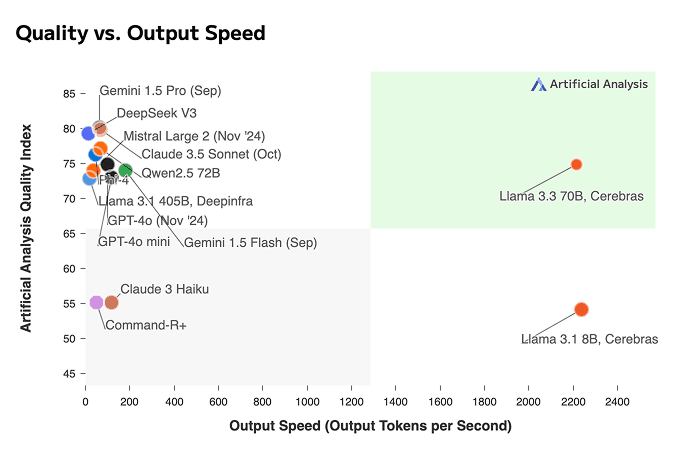
Source: artificialanalysis.ai/models
Companies Achieve Faster LLM Responses With Zero Downtime
With AI Router, we've completely avoided LLM downtime while seeing our costs steadily decrease and quality improve - all without any effort on our side.

Start Optimizing LLM Latency Today
Begin with our free plan including evaluation credits for model routing, or unlock full latency optimization potential with Pro.
- 100K requests included
- No request limits
- Privacy Mode: the best LLM without data exposure
- Smart Routing: instant answers from optimal LLM, fully handled
- Model Fallbacks
Details
Stop Waiting for LLM Responses.
Get the fastest response times for every LLM request with intelligent model routing.
Join companies reducing response times by over 70% while maintaining perfect response quality.